I will check it more carefully, but AFAICR, there is evidence to show that the most likely model is that we have a mess of Chinese rooms in our head, but the difference to the thought experiment is that it is not only Chinese rooms, but that there are elements that check, monitor and give feedback to the massive quantity of “hotel” rooms. I think this is a case were nature is not represented properly by that thought experiment.
The structure of the Chinese Room in the thought experiment is not supposed to directly reflect the structure of actual minds. Rather, it is supposed to be a structure which allows an entity to execute rograms line by line.
You can stick all the checking, monitoring, etc inside the Chinese Room by encoding it into the instruction set followed by the man inside.
Wouldn’t it be safe to say that concepts have been formed and their meaning assigned by experience?
Just a funny thought - aren’t all programs executed line by line in the first place?
I think one should substitute the man inside by a group of neurons, I guess the problem I have with the Chinese room is not that it is a good criticism of people that expect self awareness just by the advances in computer power or programming, what it is missing is that AI researchers are usually not looking at how the brain actually does it.
Checking on researchers like Jeff Hawkings (An his “On Intelligence” book), it is clear that he agrees on using the Chinese room as a criticism to classical computer researchers looking for self-awareness; however, it is clear that Hawkins also sees how one can get around the Chinese Room, if prediction and not behavior is the key to intelligence, it is a lack of a predictive memory on the part of the man inside the room that makes it equal to a regular computer, finding a way to add that element of a predictive memory to the room is one big piece in the way to make the man in the room understand Chinese.
And be a better man. ![]()
Yes, of course. What’s funny about that? ![]()
Probably not in the sense that any symbol-processing entity took a look at something in the world, took a look at a syntactically-definable element in the brain, and said (“said” so to speak) “I hereby decalre that syntactically-definable element to semantically represent that thing in the world I’m looking at.” Something like that would be required for the semantics to be of the “derived” sort I mention.
BTW FTR though I’m talking about original and derived “semantics” I should note that’s not standard terminology–standardly what’s discussed are original and derived intentionality where “intentionality” is a technical term meaning, basically, “the quality of being about something.”
[quote=“GIGObuster, post:245, topic:582787”]
I think one should substitute the man inside by a group of neurons,
[quote]
Well… Searle would probably be basically on board with that.
I said properly formed, not well-formed. A string in a language might be parsed in two different ways, for instance.
Concepts are indeed independent, but semantics is the associating of words with concepts, and the meaning of a given word in a language is definitely not inborn. The association of words with concepts was what I was describing. In fact, little children usually get the semantics before the syntax.
My understanding of the concept was that there were lots of states (cards) but that the person inside was limited to selecting a card from the stock, not creating new ones.
I think the Chinese room is supposed to reflect the way computers work.
Even in principle, how can you code every possible state of the many rooms, which will include the state of the encoder? In particular, I think you’d be required to encode the Halting Problem, which is impossible.
In a sense. But which lines get executed is determined by the data, some lines may be executed in parallel, and some lines are executed out of order if the semantics of the computation are not affected (and you don’t have a bug in your Instruction Execution Unit.)
Fair point, though there are valid answers that don’t necessitate any knowledge about the real world or the topic at hand – “I don’t know” being one of them (and if you’re locked in a room, how could you know?).
I think it’s not quite that easy – think about defining the meaning of words. Since a word is defined in terms of other words, basically no word can ever have meaning unless 1) there are some words with some form of ‘a priori’ meaning for other words to refer to, or 2) (some) words can be defined denotionally, say pointing at a tree and going ‘tree’. Now I think the first option isn’t really viable, but on an outside level, the second is trivially possible, of course. But this doesn’t generalize to mental concepts, at least not straightforwardly. So when you say:
I think that’s in fact impossible. The reason for that being that the only thing available to the mind to define concepts in the mind are concepts in the mind – there is no actual tree in the mind to point to, there is some concept (no matter whether it is verbal or pictorial or anything else) of a tree – but how did that concept of a tree come to be a ‘concept of a tree’? It is like trying to define the meaning of words when all you have are words, and nothing ‘non-wordy’ to refer to.
I’m not sure I’m getting the difficulty across. You’re probably going to say (sorry for putting words in your mouth), “well, when I see a tree, then I can just go mentally ‘that’s a tree’”, but that doesn’t work. In order to do that, when you see a tree, you’d first have to know that it is in fact a tree that you see – which presupposes the concept of a tree having already been formed. You can’t back-refer to the outside world in order to ‘ground’ your mental concepts, because such back-referral already presumes certain pre-formed concepts, because the mental realm has no direct contact with the outside world.
Computationally, it’s all the same, however, and it can all be expressed within the paradigm I outlined earlier.
It’s only an example, a simple one to get the idea across. It works equally for all kinds of representation, no matter if you use mental paint on a mental canvas, or more sophisticated means.
Would this really aid in the creation of meaning, though? Ultimately, your inner state is just a string of symbols, or at least expressible as such. So let your inner state upon seeing a tree be represented by the string ‘Baum’. You then make the association: tree <-> Baum. Does this now mean that the word ‘tree’ has acquired meaning? Only if the string ‘Baum’ has any meaning; otherwise, you have one set of symbols exchangeable for another, and that’s it.
Well, ask yourself how that could have possibly worked if you hadn’t known the size of the tree beforehand – how could you have known whether the stack is as high as the tree, then?
The thing about the blind spot is that is isn’t filled in, yet nevertheless seems to be. In the same way, things aren’t modelled (in the sense that there is, say, a 3D wireframe model of a cube in our mind when we imagine a cube), yet nevertheless seem to be.
What do you mean by “properly formed” if not “well-formed”?
This is incorrect. Semantics is the associating of symbols with things represented by those symbols. Words are symbols, but of course they’re not the only symbols. But many people believe concepts (the kind of concepts, anyway, that reside in the human brain) are best understood as symbols as well.
[/quote]
The original/derived distinction is not supposed only to apply to the semantics of words.
So far as I can recall, there’s no mention of “cards” or “states” at all in the scenario. There’s a library of instructions for the manipulation of symbols, and the instructions make no mention of the semantics of any of these symbols. That’s pretty much all that’s said about what’s in the room other than the man himself.
Basically, yes, at a very high level of abstraction anyway. Maybe it’s more accurate to say it’s supposed to constitute a system with exactly the same input/output functions as some computer or other, at least insofar as that computer is executing a program that’s supposed to make it understand Chinese.
Sorry, I’m not sure what “rooms” you’re referring to here.
But in any case, you can encode as many states into the room as you can any normal computer. I’m not sure why you’re asking for more than that.
Yes, but the entire mapping could be “I don’t know”, I thought we were trying to create a valid mapping (aside from the stuck in a room bit).
What? Why not?
As we grow and learn in our environment, we establish an association between our various senses - visual with auditory (see a tree, hear “tree”), etc.
With enough of a base, new things can be defined in terms of the already learned things.
Do you disagree that this process happens? And that we are able to understand new words/concepts based on explanations of already understood words/concepts?
What is available to the mind is input from multiple senses, including experience with those senses over time and with various types of physical interaction.
All of this creates some type of idea/concept/representation of “things” from our environment.
No, it simply is not a problem at all.
The concept of a tree in the mind has no need to point to a “real” tree in the environment and of course there are no trees in the mind - that is not at all what is going on in the mind.
The mind is encapsulating all of it’s sensory input into “chunks of stuff in the mind” that can be referred to, form associations and get manipulated.
The mental realm refers back to a pattern of sensory input it experienced in the past.
That’s what it does.
Where is this difficulty? I am honestly really pretty confused by what you are getting at here. It almost sounds like you are saying the following:
- The brain does not work by breaking down sensory input into patterns and storing them
- The brain does not have the ability to associate the written or spoken word “tree” with the visual patterns it has experienced in the past
I assume you are not saying those things because that appears to be a pretty basic function in animal’s brains - so maybe you can re-explain your position, I am not understanding.
You mean they are computationally the same because, excluding the number of operations, they ultimately arrive at the same mapping?
Possibly/probably. But the two ends of the spectrum are not computationally possible - more operations or state required than there are atoms in the universe.
That’s why humans use the middle route (IMO) - it’s an optimized compression and general problem solving method - balancing the amount of state to be retained vs the energy to compute vs speed to compute, etc.
Well, you and I aren’t going to agree on this one by going back and forth.
How about this: the logical extension of what you are saying is that humans can not calculate anything they did not already have the answer to. Correct?
I don’t like introducing strings and symbols because I don’t think the brain works that way.
But as long as we agree that ‘Baum’ is a place holder for the representation of tree in the mind then - yes, the only meaning it has is the meaning that is sitting inside the brain which was acquired through previous experience through the senses - to me that is valuable and valid “meaning”, but it seems you think meaning should be something more?
I know exactly why it worked. I’ve even done it multiple times since then as a test to make sure my initial gut feel wouldn’t be just as accurate.
The visual scene exists inside the brain (at least for me it does).
The size of an object relative to the visual scene can be determined and roughly duplicated.
An image of similar size can be placed next to the perceived object, and this can happen repeatedly.
Count the number of duplicates that fit.
Why do you think manipulation of a visual scene to extract additional information can’t happen? Can you clarify what information you think I was already storing that allowed me to determine the size of the tree without any further manipulation?
-
As previously stated - blind spot filling in vs explicit mental manipulation of a scene or image are very different things - you can’t use one to argue for or against the other
-
I can’t tell you what form the representation of the cube takes from a physical standpoint inside the mind - nobody can and that’s not important - what is important is that we are able to combine and manipulate 3d objects to perform calculations.
I haven’t worked on grammars in ages, but you can define an ambiguous grammar, where one string may have two different, and correct, parsings. I was calling that string properly formed, but not well formed. You run a grammar through yacc and lex and it will tell you if you have a mistake. I’ve made plenty.
[/quote]
I was writing in the context of human speech learning. Any token at any level has semantics. When my older daughter was very little, she had a kind of grunt for an ice cream place in Princeton she loved going to.
I remembered the instructions as being on cards, but I absolutely agree that the scenario, as I remember it, had no semantics associated with the cards.
Half Man Half Wit, I was thinking about the 3d wire frame cube, testing some rotations in my mind, and then I was doing the same with a sloid cube and I realized it is much easier to do with the solid cube.
The wire frame cube is tougher to keep track of, especially when the corner approaches center and multiple lines begin to get confused due to lack of location uniqueness. Whereas the sold cube doesn’t run into the same problem.
If we aren’t actually re-interpreting the scene - why is my mind better able to deal with the scene that is easier to re-interpret? I can feel the problem internally, my brain is definitely not just transforming and projecting from a base image for each step in the rotation - it is using clues from the last image to determine next position.
Right, but his model of how this happens is that the computer has a big look-up table of potential inputs or sequences of inputs, and produces output based on the current input and previous sequence. That model, I believe, does not allow you to construct a Turing Machine (which can erase and overwrite its tape) and thus does not allow the model to do all the things computers can do.
I was referring to GIGObuster’s observation that our brains could be modeled as a bunch of rooms.
But the room is a state machine, in essence, if an impractical one. A computer is a nearly infinite number of state machines, which can be constructed on the fly.
I think the real problem here is that Searle is not really saying anything about the room knowing Chinese when the person doesn’t. After all, we know English and our neurons don’t. He is implying that the room would never pass a Chinese-understanding Turing Test, which it wouldn’t. If he allowed the structure of the room to be powerful enough to pass the Turing Test, how would you be able to distinguish the room understanding Chinese thanks to its “program” from the room understanding Chinese because the person threw away the cards and really understood Chinese?
RaftPeople, I’m not going to respond in a point-by-point manner, this is getting too unwieldy. Basically, the problem I have regarding your theory of meaning is the following:
Think about trying to translate a sentence in an unknown language. For instance, the sentence is ‘quixopotl ai cuarantes y lonagas mochas’. Now, you have a dictionary, which you use to translate the sentence. Unfortunately, the dictionary translates only to another language unknown to you, so that now the sentence reads ‘levieux alais-la ciliete ca-tue ilieges unais’. Have you gotten any nearer to the meaning of the sentence? Of course not. A third dictionary you use to translate the sentence to ‘lebenich seian latage anich niese unzus’ won’t help, either. No matter how often you translate the sentence, you’re not going to get closer to its meaning in this way, I suppose we can agree on that.
Of course, you might get lucky, and find a dictionary that translates into a language you know. Or, you might actually know one of the three languages already. But let’s suppose you actually know no language at all – do you think you could learn one, just being supplied with a text, and an endless supply of dictionaries to translate it? Because that’s the situation in the mind – all you have are various mental languages to translate into: pictures, sounds, words, thoughts, feelings etc.
So let the first ‘language’ be what you see, the second be what you hear, the third be what you see. You hear ‘tree’, you see a picture tree, you feel a “tree”. You may establish a mapping ‘tree’ <-> tree <-> “tree”. This mapping is identical to the one between the three sentences above. But if the mapping in the case of the unknown-language sentences did not help you to get to their meaning, then how is the mapping between the ‘tree-concepts’ supposed to help you discover the meaning of ‘tree’, tree or “tree”? Only if you know any of the languages – only if you know what either a ‘tree’, a tree or a “tree” is – does the translation help.
Does that make the problem clearer? It’s essentially the regress problem, applied to the hypothesis of the existence of a ‘language of thought’ (here’s the Stanford encyclopedia entry on that).
As for how you could estimate the height of the tree, well, let’s suppose you had no idea of that height at all. Then you draw a mental picture of the tree. Then you draw your house mentally next to it. Then you stack your house on top of itself. Then you stack again. And then you get stuck in an infinite loop, because the terminating condition that the height of the stacked houses equals the height of the tree (to within some error) never is met, as you don’t know the height of the tree. Knowing the height of the tree is necessary in order to mentally draw the height of your house and the height of the tree in the right relation – and knowing that relation is a prerequisite for your mental manipulation to work. So you can’t in fact have extracted any new knowledge from your mental manipulation that was not already necessary in setting up the mental representation.
This doesn’t mean that we can’t do mental manipulation to convert one piece of knowledge from one form into another, and in another form, it might become more useful for certain tasks (trivially, in order to describe someone’s looks to another person, we must first abstract from our internal pictorial knowledge of that someone to a verbal form, which we can then relate). 2 + 5 and 7 are just two different representations of the same data, one ‘procedural’ (though on a very low level), the other direct; but the knowledge of the rules of addition, plus the two values 2 and 5, uniquely determine the outcome to be 7, thus, in that sense nothing new is learned in carrying out the addition. How exactly data is stored is then a question of efficiency.
OK, I’m going to steal a page from Dennett (literally). Here’s a picture for you, and a simple task: check if, through the black aperture, you could see the cross. If you actually generate a visual representation of the object in the picture in your mind, this should be a trivial task; certainly one could set up the problem on a computer in minutes, have it draw and then rotate the object, and just check whether the cross is visible.
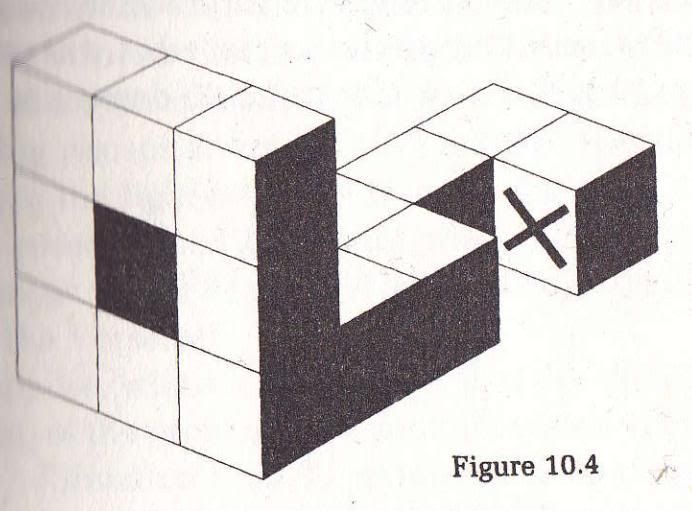{kind=link}
However, if you’re like me, you’ll find it astonishingly hard to solve the problem, and if you do, you won’t hold much confidence in your solution. But why should that be so? Certainly, we are accustomed to mental visualizations – or other kinds of representations – of far greater complexity; why, if our minds are capable of creating those detailed models, should it have such a hard time with such a simple one?
I believe the reason is that these ‘detailed’ representations are in fact for the most part a sham. Just like blind spots in the visual field, there is, in fact, nothing there – but there’s also nothing there to complain, so we don’t notice.