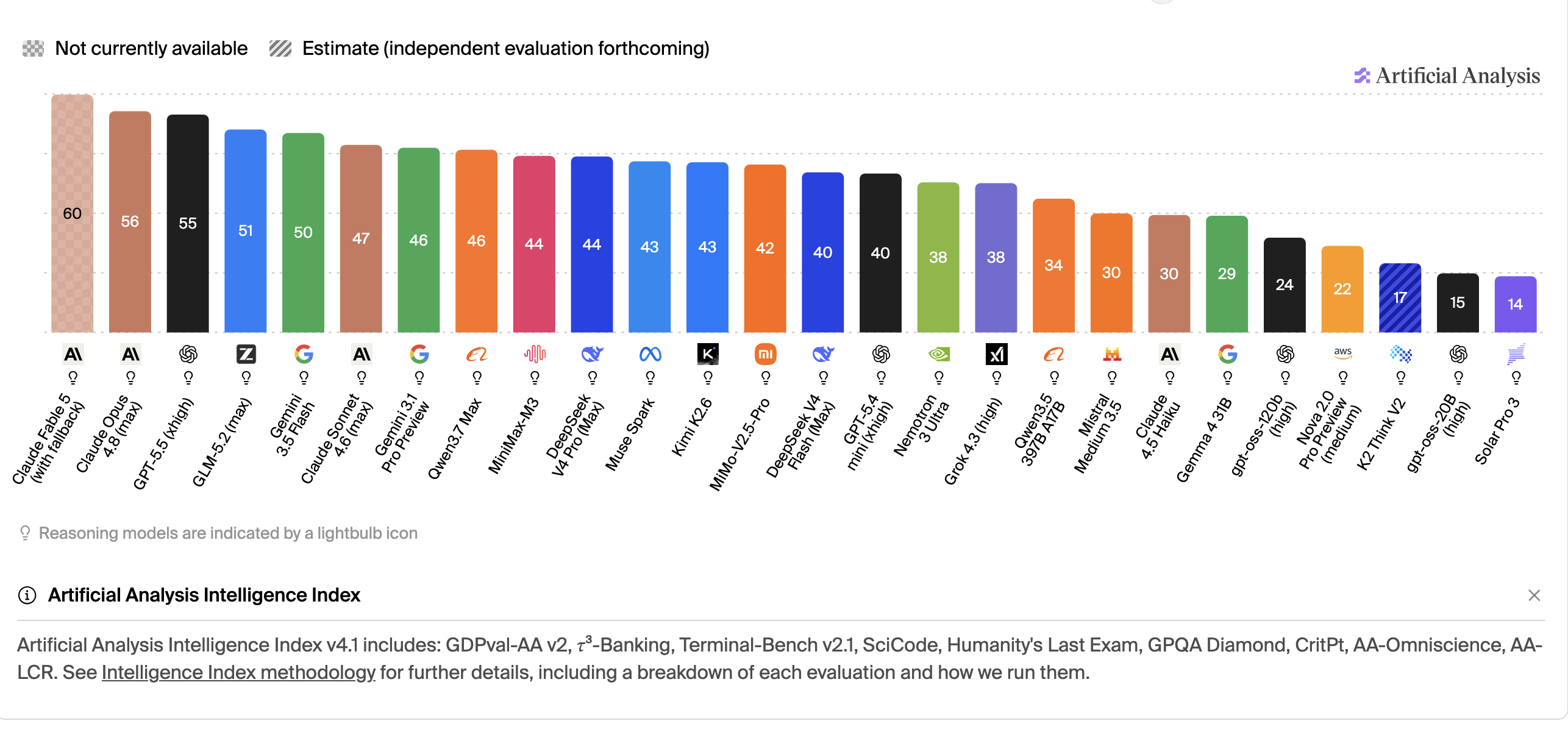
The specifics depend on which particular vendor you’re talking about, but generally, paying gets you some combination of:
- Access to better models (like Opus [and Fable, before the US gov censored it] instead of Sonnet, or GPT 5.5 Thinking instead of Instant)
- Access to agents and harnesses — long-running sessions that can call tools on their own, see the results, keep working on it until it’s done, etc.
- Longer contexts (how much the model can keep in memory before it starts losing track of what it’s working on)
For Claude, going from free to Pro is a big upgrade due to the above. Going from Pro to Max doesn’t get you anything except more usage.
If free is working fine for you, awesome, no need to pay for anything.
What I pay the $100 for is primarily higher agentic usage to support my hobbies. One, it makes apps for me (like a SDMB long-thread summarizer, a usage analyzer for my printer ink subscription, and a few other things I can’t quite remember right now). I also sic it on long-running research tasks so I can learn about random things like 3D printing — all the printers and techniques and inks and filaments and bonds and pros and cons blah blah blah, mountain biking, insurance regulations, business and nonprofit law, etc.
On the $20/mo plan, I was frequently hitting the limits and having to wait half a day before being able to continue.
It’s probably mostly the agentic coding that’s eating up the tokens, though. I used to be a software developer, but I haven’t written any code in months now, just asking Claude to do it all. The research is probably just a small % of it. In fact you ask Claude to break down what’s costing it so much:
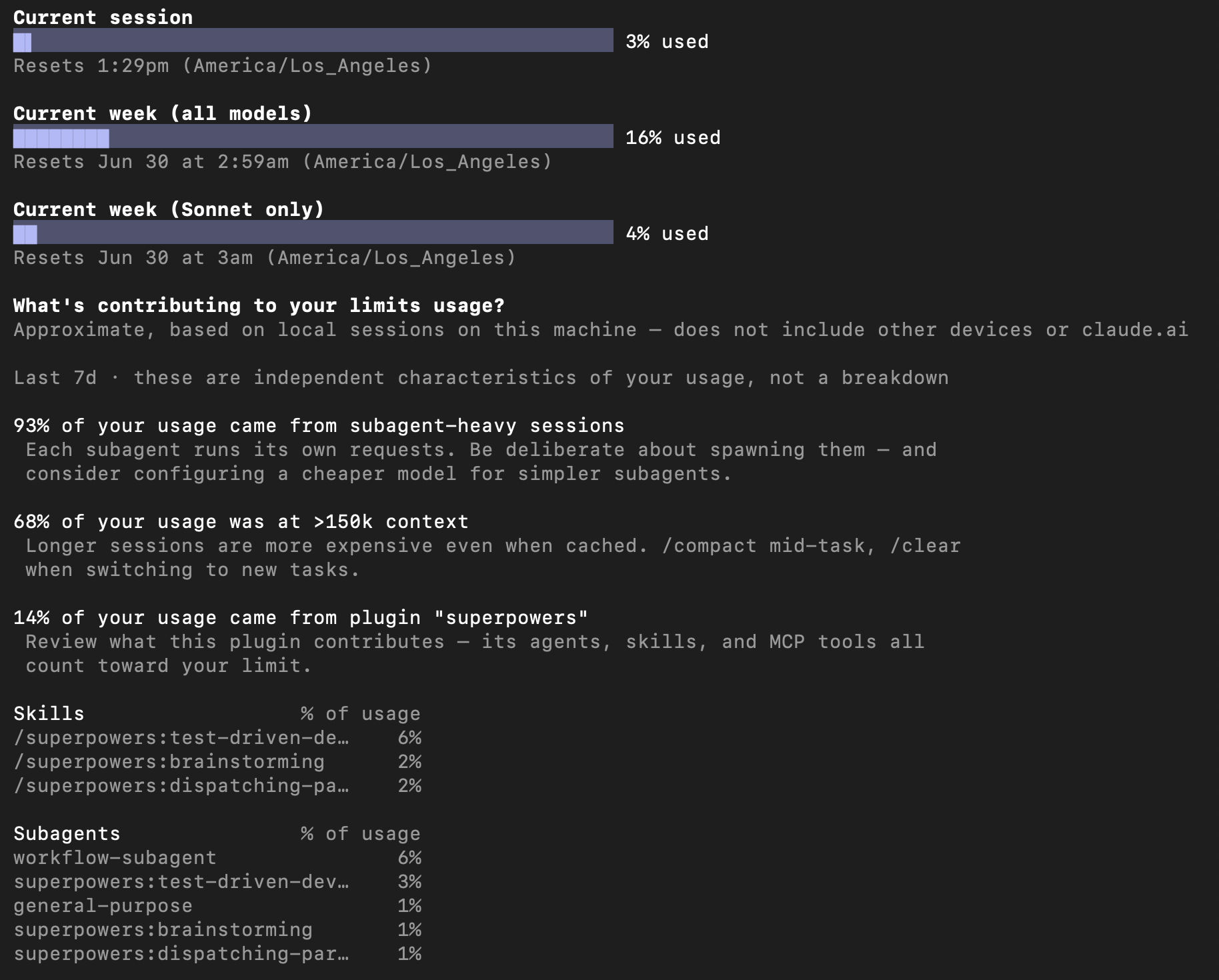
In this case the “subagents” are LLM sessions spawned by my main request. I give Claude an overall goal of what I’m trying to do, then it’ll think about it and come up with a complex workflow (sometimes taking multiple hours), fan it out to multiple sub-agents that each do one specific thing, then review their work with other subagents, then try to refute it, before it all comes back to the main agent for the final report and synthesis. So think of it this way… instead of you going back-and-forth with a chatbot, taking turns one after another, Claude itself chats to a bunch of other Claudes, dozens at a time and taking hundreds of turns each, over the course of a few hours. It’s basically a meta-Claude handling all the mini-Claudes.
No, two different things:
Reasoning is “think really hard about this problem before you write anything down”. Deep research is “go to the library and do a literature review and summarize it all”. Agents and harnesses combine both of the above, plus many more tools, into a semi-automatic workflow spanning minutes or hours for particularly complex tasks — primarily but not necessarily coding.
Like the SDMB summarizer I built uses a combination of classical computer code to fetch all the pages of a long SDMB thread, then splits up the result into chunks and sends each chunk to a subagent to read, summarize, and highlight, then the subagents hand off their reports back to a main Claude instance that summarizes all of it together at the end. It uses code (that Claude itself wrote), but its purpose isn’t coding.