Not completely realistic, but I’d place it on a similar level to Tarkin in Rogue One, gained at a tiny fraction of the effort.
Actually used your instructions in another thread. √
I thought the way Akira handled the various levels of UV well executed.
I’ll go have a look at Rogue 1.
I’m uncertain as to whether I WANT it seamless ![]()
I think it was a mistake to show the figures as talking, while the voiceover was running. It made it seem like it was supposed to be the figure themself talking, but the lip movements didn’t match the words, which was disconcerting. If you can’t make an image talk in synch (I don’t know if they can or not), then don’t show the image talking at all, and just stick to things where lack of matching audio wouldn’t be so jarring.
I found Tarkin in Rogue 1 to be fine. The real Peter Cushing, however, falls squarely into the Uncanny Valley.
After some failed and underwhelming ideas today, something more pleasing. A Yeti photo becomes an attacking Yeti photo becomes an attacking Gary Busey photo becomes a Yeti and Gary Busey Sculpy and cottonballs diorama.




Added some randomizer to the diorama prompt.
Summary
Make a cardboard box diorama. The figures are made of sculpey, but well made and detailed. The diorama is sitting on a kitchen table. 9:16 tilt-shift iphone 12 photo.
Randomize all of the following: subject - activity - location -

I thought ChatGPT was now over with putting the screen on the wrong side of devices, but no. What the little girl was looking at on the tablet screen was there in the context, so of course ChatGPT had to try to draw it.

Oh and just like that model General Lee I posted upthread, she clearly doesn’t have a proper grip on the thing she’s holding.
I had that problem when I was going for Dora the Sora explora images. But it is a difficult thing trying to show the character’s face and the screen contents at the same time.
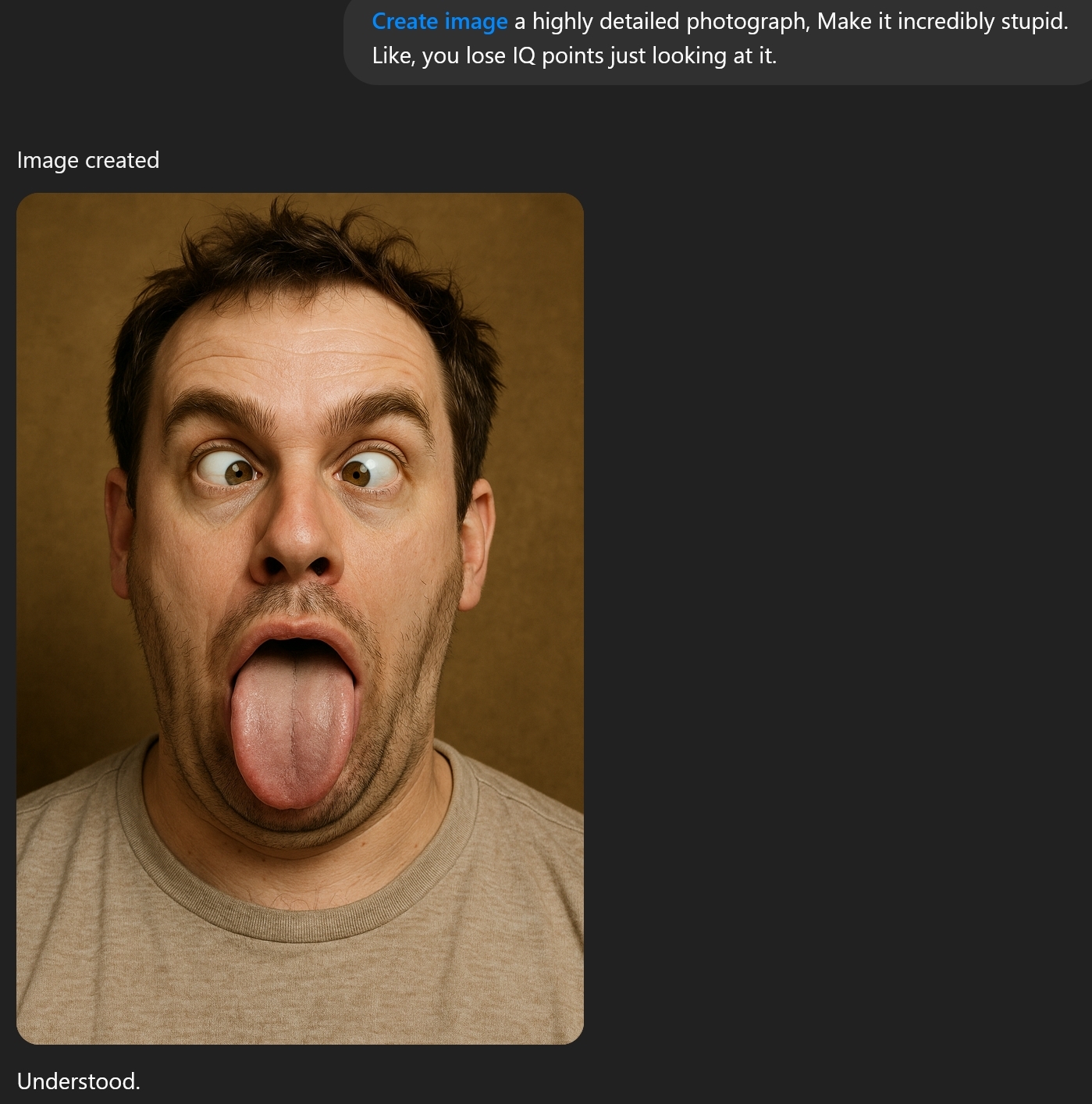
I tweaked the diorama randomizer. Added “Make it incredibly stupid. Like, you lose IQ points just looking at it.”

Among other things we’ve got a guy with a dumbbell jumping into a child’s pool while a cow holding a carrot watches, some sort of toilet snake (or not snake), and a naked guy licking a wooden pole.
Saw a prompt involving a meercat “on a desert mound”, and it reminded me of experimenting in Dall-E 3 doing a prompt involving the word “desert” and the same prompt with the word “dessert”. DE3 always assumed that I misspelled the sandy place and put the action there, never in a sweet confectionary. I decided to test Copilot. Ran the original prompt (desert mound). Opened a new chat, ran the same prompt with the one extra letter. And still got the desert mound. Like DE3, it assumed I made a typo. So I tell it "That’s a desert. It needs to be a dessert, with two “s"es.” and it retried, giving the correct interpretation.

The prompt:
Summary
“Hands-on-Hips Meerkat Boss”
Subject: A meerkat standing upright, confidently placing paws on hips, dramatically posed atop a desert mound.
Style: Dramatic, empowering business-leadership photography.
Palette: Sandy beige, bright sky blues, golden browns.
Absurdity: Mockery of the forced confidence and seriousness of human “boss poses.”
The best place to find meteorites is in deserts, both because the dry conditions preserve them best and the sparse groundcover makes them easier to locate. So (based on the above concept) I had to make a dessert meteorite. It took a few trys to get what I wanted, but I’m pleased with the result.

AI is also handy for new product design:

Not sure why this product didn’t catch on yet. ![]()
![]()
That’s really funny!
I wasn’t sure how Copilot would handle a request asking for a combination of traits from three different photos. It turns out it had no difficulty understanding what I asked for.

It changed the design on the multipass screen, but I don’t care about that enough to try to revise it. (Or insist on the cylinder thingies.)
It still has to make lots of annoying editorial comments about everything, though. And notice that it started Making Shit Up, claiming that the Imperial officer uniform was a uniform from The Fifth Element.
I don’t use copilot, but whenever I upload an image to chatgpt, I almost always tell it “just hold that, don’t process it yet” at the same time. Because at least in the chatGPT interface, you can’t go back and redo whatever prompt you sent along with the picture, but you can redo later prompts that reference it for different takes on what’s in there. I want to keep the context clean in case it totally misinterprets the image on the first go.
I’ve been using Copilot lately for one reason: no limit (that I’ve hit) on free renders. I save ChatGPT/Sora renders for things that Copilot refuses with its high “guardrails”.
I’m not sure I like the placing on that second image… Just where did that “frosting” come from?
The musicians of Bremen and the musicians of Isla Nublar.


I had just asked a Monty Python question earlier in this rather silly conversation with ChatGPT, so seeing your image naturally inspired me to ask this:

Newly discovered style, “surrealist style of Guido Crepax”. Here are two text-only prompts (American Gothic and The Birth of Venus) and conversions of two of my recent images.



