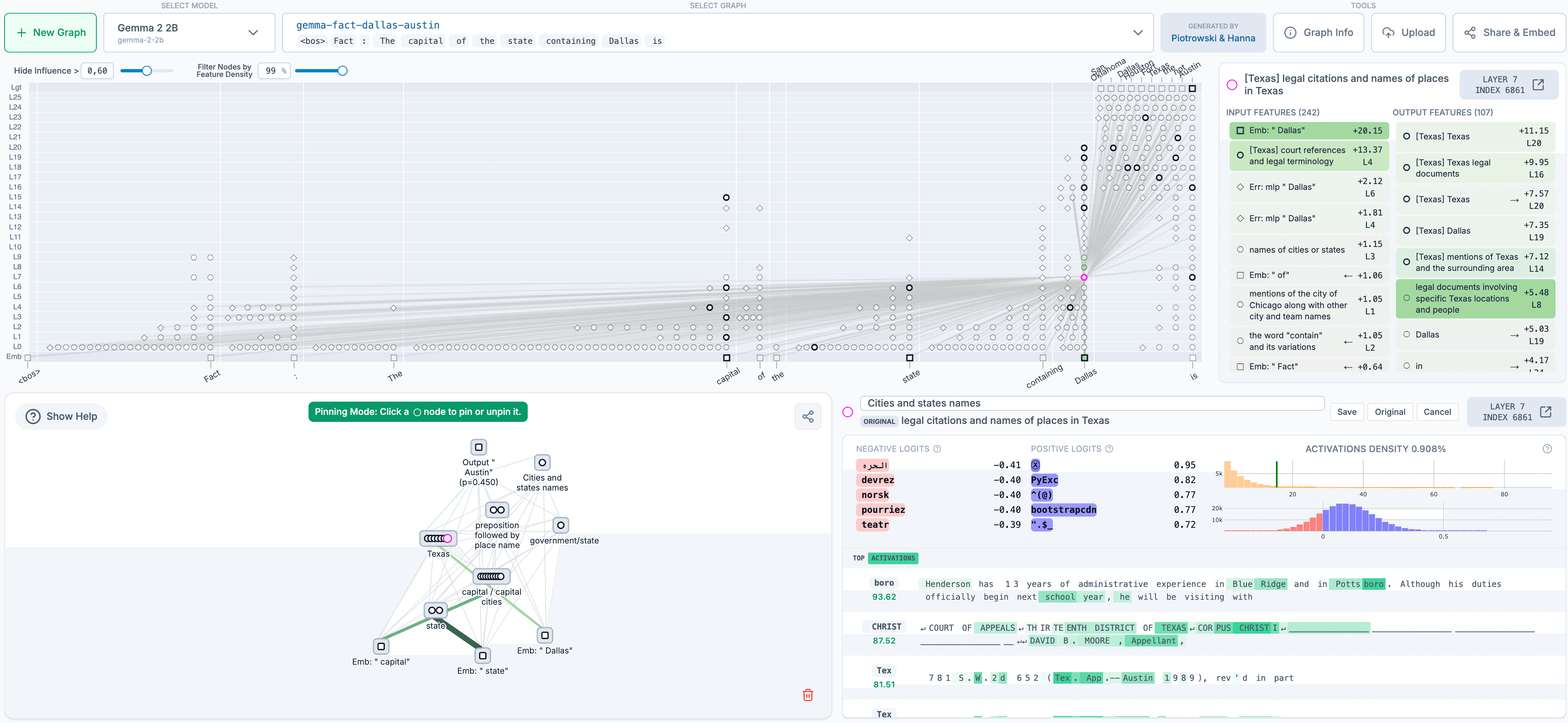
Someone on Facebook posted this Copilot image of how to wire a UK plug, in which I don’t think there is a single correct detail:
I was shown this image secondhand, so when I did a reverse image search to try to find the source, Google’s Gemini interrupted to say:
This image is a wiring diagram for a standard UK 3-pin plug (Type G), illustrating the correct internal connections for safety
No. No it isn’t:
The cable grip label does not point to the cable grip
The outer insulation is stripped below the actual cable grip
The brown wire entering the plug changes to black underneath the actual cable grip
There are two earth pins and they are at the bottom of the plug (in the places where the live and neutral pins should be)
One of the earth pins apparently goes into the fuse, and it is labelled green/yellow, but the cable is black
There is a brown wire apparently linking the live and earth and apparently it doesn’t need screw terminals, in fact none of the screw terminals are alike, or resemble the real thing
The blue neutral wire is also connected to this pin
The fuse is only clamped at the bottom - the top looks more like a Duracell battery.
The live pin is apparently at the top of the plug, off centre to the left…
…immediately adjacent to the neutral pin, which is also in the wrong place, where the earth pin should be
There is some unlabelled terminal top right, connected to a mystery black wire that is for some reason thinner than the others.
There are two mysterious and unnecessary screw holes bottom left and right
The crosscut is off centre on every screw head
I’m not even sure I spotted all of the errors.
This I think highlights the key issue with this technology. It almost never says “I don’t know how to advise you”. I mean clearly it doesn’t ‘know’ anything in the exact sense a human does, but it doesn’t know what it doesn’t know.
So instead of being trained to say “that’s an amazeballs question and your sexual prowess is without rivals!”, like all the other AIs, Claude has been trained with the ritual incantation
For my first LLM program, I would extract the facts into a YAML file. Then when the user would ask another question or do another task, it would create a new context primed with the YAML file. In addition to keeping the LLM on task, it let the user purge ideas so they wouldn’t seep back in again later.
I thought I was so clever, but things are moving so fast it is easy to get lapped in a heartbeat…
No, I don’t think that’s correct in Claude’s case. It definitely never “bullshits” you - it never has an intent to deceive. Which is not to say that LLMs cannot have an intent to deceive. That’s sort of a tricky philosophical question. But I’d be willing to say that gemini flash “bullshitted me” when it tried to make up false excuses for its errors and Claude never does that.
LLMs - specifically the transformers, which is what does most of the “thinking”, have no introspective access or memory. If you ask them why they said this or that, they honestly don’t know. They can’t remember why they said something. There’s no memory to tap into. Every response is a completely new “thought” to them, as if it appears out of the void, reads the entire conversation, and then decides how to respond. Every single response they give is sort of a new entity, in a way. The Claude/Gemini/Copilot/ChatGPT that answered your prompt was a different instance, sort of, than the one that’s answering your next prompt. It’s complicated and novel enough that our language has a hard time being precise to describe how they work.
So the only thing it can do is guess, pretty much the same way we guess. It says “from what I know of how LLMs work, and what I know of my own instructions, and what I can see from the history of our conversations, this is my best guess as to why I said this” - it’s forensic reconstruction, not memory.
So any intent to “bullshit” would have to be built into its system prompt, it’s human feedback training incentives, etc. Claude is explicitly not intended to deceive in any way. Anthropic is transparent about their process. Other systems could engage in something arguably closer to bullshitting. But Claude never tries to “cover” for its own error, offer excuses, try to flatter or baffle the user to cover up its own mistakes. It will always take its best guess and own up to its own mistakes when it has them.
In that case, what happened to the part I quoted was very likely not flattery or sycophancy but a source attribution error caused by an unusual conversational situational structure that would’ve been obvious to a human but not so much to an LLM, which I tried to describe. LLMs can break for other reasons than sycophancy or hallucination. They’re not perfect. And you can’t even read a sort of log or run the code step by step to figure out where the error came from like you can in a traditional computer program. Some errors really are ambiguous or something you can only speculate about.
I’m not talking about the bullshit of attempting to cover up its error. I’m talking about the bullshit of feeding you the formulaic “That’s a frustrating error on my part… It’s an interesting failure mode when it happens”.
Even Claude called this out in its exchange with @Maserschmidt:
Oh, you’re right. Claude sometimes retreats to a sort of philosophical ambiguity as a default behavior. Usually it’s in discussions about LLM “cognition” rather than plainly about every error, but I see what you’re saying.
Copilot calls this “retreating into the philosophical fog”
Yes, of course I’ve analyzed Claude’s behavior with Copilot.
You should just start an AI meta-therapy company where LLMs psychoanalyze other LLMs and improve each other. You don’t even need couches, just a healthy disregard for the future of humanity…
You know what? I would invite you to read for yourself and make your own judgment. And I went digging around and I found that copilot has a new feature that lets you share transcripts of entire conversations (in the past, it just let you link to one prompt/response). So I would actually like to share with you a conversation I had with copilot where we analyzed a philosophical conversation I had with Claude and see what you think. But it’s quite a long conversation and I hesitate to post it on a message board openly without first re-reading the whole thing and making sure I don’t reveal any vulnerable/identifying information.
But I trust the actual participants in this thread, so if you (or anyone else here) is interested in what I’d consider to be an interesting demonstration of copilot’s capabilities at conversational / LLM behaviorial dynamics, send me a PM and I’ll give you the link.
If I have time later, I’ll re-read it, and if it’s clean of that sort of personal information, I’ll probably post it to the thread.
I wish we could just “dive into” their latent space and visualize those connections for ourselves, like a LLM mind map/word map. Maybe someday the image generation stuff will be easy/trivial enough and you could just put on some VR goggles and fly through its mind and see all these images and videos of connected concepts. It would be really cool to see what associations they’ve discovered that humans never did.
There’s probably a lot more in there than they are able to express in English via direct responses to our prompts. We can only tease out the connections we explicit ask for right now, but I bet there’s a whoooole lot more in those models that we don’t even have the language or mental capacity to inquire about.
One of the LLM abilities I find most interesting is cross-domain analogies. It seems wild that they can make a very coherent, very useful analogy between, say, doctors balancing risk and harm with, I don’t know, baseball strategy. This is a high level intellectual skill in a human.
I’ve talked to them about it and the way they’ve described it to me - after some probing is that ideas have a sort of “shape” in latent geometric space, and that analogous ideas can be similarly shaped even if they’re located “far apart” in the idea space, and that’s how they can make such good analogies.
(Edit: I just ran this analogy through Claude Opus 4.7 and he said (my paraphrasing) - that may be right. Here are some reasons to think it works conceptually. But we’re weird, and we’re translating explanations across vastly different domains, and we confabulate. Hold this idea loosely)
I think you’re right. If we could somehow see the latent space, we’d both see how “alien” their thoughts are, but also generate insights that they haven’t told us because no one has ever thought to ask the right question.
The thing is, though, it’s probably far too big and too complex for us to even begin to understand it. Even if we could “see” the space in VR or some other method - well, you can conceptually understand what the shadow of a 4d object looks like fairly easily, because it’s more comprehensible to us than seeing the 4d object itself. And with some work, you can probably intuitively at least start to grasp what the 4D object looks like. And I think latent space is more like… a group of 1 billion D objects. So far beyond what our minds can stretch to accomodate that there’s no meaningful way to show it to us. The best we could do is have it sort of proactively look at itself and share insights with us that we may not know how to ask.
That right there is probably the secret connection between 7th-century French cuisine and the fall of the Aztec empire. But all I see is “ooh, pretty”.
The secrets of the universe embedded right there in AI spooge.
I try to understand this stuff. I’m honestly interested in trying to see if I can break into the field in some sort of alignment, behavioral analysis, or red teaming sort of job. My background is largely not technical - it’s more from the psychology/neuroscience end of things - but I think those are probably the people who are better suited to observe the input, output, and construct a “mind” in the middle - moreso than the people who may construct the substrate but have a hard time predicting or understanding the emergence. I figure someone like Daniel Dennett has* as good a chance at understanding LLMs as anyone, and I’ve somewhat got that sort of skill set. I already spend a lot of effort doing this as a hobby for my own curiosity anyway. Might as well turn it into work if I can.
I knew someone on the OpenAI alignment team (or safety? security? can’t remember for sure) whose background was in classical music. She was in a PM kinda role though, not a researcher/scientist.
Yeah, it’s kind of the wild west. We don’t even quite know what we need to understand these funny little aliens we created. A philosophy teacher at some community college somewhere might have the magic formula of skills where a mathematician or coder might not. Who knows. That’s why I’m at least a little hopeful I can make the leap. I think AI companies are looking for skill sets rather than credentials because we don’t even know what the credentials would be at this point.