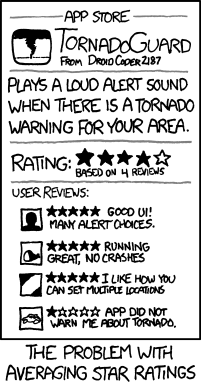
Nowadays, it’s become routine for all of us to compare google/amazon/tripadvisor/whatever reviews before making a purchase or choosing a restaurant/hotel.
Usually, these reviews are on a scale from one star to five, with the average of all reviews determining the score. However it is well-known that you should also check the overall number of reviews submitted as it might be safer to opt for a product with an average of “only” 4.7 but 200 reviews over another with a 5-star score but only one review.
That’s when it gets tricky. If I compare two products with scores of, say, 4.9 (156 reviews) and 4.7 (387 reviews), how can I decide which one is the best, or at least the best-rated? If I simply multiply the averages by the number of reviews, I get a number that gives me an idea (the bigger, the better), but which is also completely out of proportion with the original grading system. Is there a mathematical formula that can bring this unwieldy number to something of the same order of magnitude as the 1-5 star system, so that I can manipulate it with values that are easier to grasp?
IANAMathematician, so bear with me, but it is my understanding that in statistics the standard deviation, being the square root of the variance, is used partly for that reason: it brings the values back to the same order of magnitude as the original data. Is this correct? And if yes, could I use something similar for internet reviews?
It’s also not just the number of reviews and the average, it’s also the distribution. I’d be more inclined to choose a lower rated place if it has an unnatural split of 5-star and 1-star ratings that looks like the result of malicious review-bombing.
It’s not an easy analysis. It’s as much gut feeling as objectivity.
The core idea of a statistical metric is that you are hoping to compare the two scores, not just the average scores, but the shape of the distribution of the scores. In doing this you are testing the proposition that the two scores are the same within a certain chance that the proposition is true just by luck.
The problem you have is that you don’t have actual knowledge of the properties of the products being scored. By which I mean that you don’t know what score either would get as an intrinsic property of the product, nor the shape of the distribution they would intrinsically attract. What you have are two sets of estimates of these parameters. A very low number of scores from which estimates of the average and spread are created leads to a weakening of the applicability of the test. In principle, if you only have one score, the estimate of the spread isn’t even defined. So you are quite limited in what can be done. But this is a well understood question.
However once you have say past 100 reviews you should have a quite reasonable estimate, and a very standard can be test applied.
Standard deviation is the usual estimate of the spread. But it presupposes the nature of the intrinsic distribution. With reviews this is a big problem when you get a pile of bad reviews and good reviews, and the distribution is bimodal. The you have a whole new set of issues to manage.
There’s another problematic issue in Amazon reviews that could lend itself to mathematical analysis, based on additional data that could be gathered automatically. It came to light when my daughter bought me a pocket telescope for my birthday.
The telescope was terrible! Views were blurry, hazy, and distorted.
Curious, I looked its reviews up. It had five 5 star reviews and one 1 star review. So, for each 5 star review, I looked up the reviewer’s other reviews. In each case, the reviewer had dozens or hundreds of other reviews, all of them 5 star, and for products that fit no obvious pattern except that I didn’t know any of the manufacturers. There’d be fingernail polish, socket wrenches, book repair tape, mineral supplements, dog collars, all manner of unrelated products, reviewed as 5 star by each reviewer.
The reviewer who gave 1 star had maybe 10 or so other reviews, with a range of stars, and most of the items were somewhat recreational.
At least some of this analysis was quantitative, so I can imagine an automated shenanigans detector.
By the way, the problem of taking averages and numbers of reviews into account together is addressed by Student’s T statistic, though this does assume Gaussian distribution.
It does, and it ensures that the standard deviation is in the same units (centimeters or hours or “stars” or whatever) as the original data and the mean.
There are ways to statistically compare two different data sets that allow you to compare them. But if one of them is more trustworthy than the other due to things like being more likely to get flooded with fake reviews, or having different sorts of people with different criteria doing the ratings, I don’t see how you could establish that purely with mathematics.
My take on reviews is they are pure Garbage In, so any attempt at analysis will be pure Garbage Out. I certainly agree with the legit statistical issues brought up by @Francis_Vaughan and the cheating issues mentioned by many people but especially @Napier.
But wait, there’s more!
Reviews are what we call a “self-selected poll”. Even if we could magically strip out all the cheaters, the roster of who makes a review is not a random cross-section of the actual customer experience. As a general matter, most people are much more inclined to give bad reviews than good. So if they buy a crappy product they are motivated by anger / disappointment to write a bad review. But when they buy a good product, they don’t bother to review it. But the size of this effect is not quantifiable.
Putting aside the question of fake or irrelevant reviews for a second, assuming you had two trustworthy and comparable datasets but one with a higher # of reviews, I think the OP’s original question is still meaningful: How do you combine both the star rating and # of reviews into a unified rating that takes both into account, sort of like a “weighted average”?
For the actual underlying problem, you really want to read a selection of the bad reviews and the good reviews. Google, at least, automatically gives you a selection of “typical” reviews of each type, as well as an AI summary of them. If the typical bad review is based on things irrelevant to you, or because the product fails to break the laws of physics, or something, that means the product is probably good. If the bad reviews are “doesn’t actually work”, though, that’s different.
Or, you can get a situation like I’ve seen on reviews for Indian restaurants: The reviews are all either “I’d never eaten Indian food before, but this was pretty good”, or “Of all of the many Indian restaurants I’ve eaten at, this was the worst”.
Which immediately raises the question of what algorithm they use to select that sample. I’m not suggesting malign intent on their part, but whatever logic they use may be the sort of thinking that we and the OP can use too.
Speaking to my personal habits …
On the rare occasions I’m comparison shopping by reviews, my approach is to first read only the bad ones. If those people are evidently idiots, or are bitching about e.g. customer service issues, not the product, I can throw them out of my informal mental sample space.
Then I turn the the good reviews and try to throw out the hagiography. Usually about then I give up on reviews altogether and make my decision solely on the stated features of the product versus the price.
Well, they’ve been doing it for a lot longer than GPT-style LLM AIs have been around, so it’s nothing that complicated. I think that it mostly just looks for keywords and their synonyms in the reviews. They might also have a “Was this review helpful?” checkbox, which is simple enough to interpret.
It is even worse than that; there are known biases and inequities in reviews. For one, reviewers have differing expectations about the quality and functionality of a product, and often, someone will leave a poor review just because the product didn’t meet their specific needs even though it is obvious from the description that they were in error. Another is that people generally aren’t inspired to post middling reviews; on most products, the majority of reviews are a combination of 1, 4, and 5 stars, resulting in the noted bimodal distribution. And sometimes people will leave a poor review for an otherwise excellent product because they were unhappy with the speed of delivery or customer service (which drives me nuts because that shouldn’t be part of the product review if it is being provided by an independent distributor). So Amazon reviews, and in general most online reviews by customers are an inconsistent and unreliable body of data to even perform statistics, especially if the number of reviews is only a few dozen or less. This is even before you get to the the issues of intentional or malicious manipulation of the review system.
Or dumb-ass reviews.
“Great item but 1 star since it arrived late.”
“1 star. I wanted the blue one but accidently ordered the green one and they didn’t send me the blue one.”
“Haven’t received it yet, but my friend that has a similar item from a different company and he didn’t like his. One star”
I’ve seen ones where it seems like the reviewer refuses to ever give a five star review.
“Greatest item I’ve ever bought. Does everything it promises. Cured my wife’s stage three cancer. Four stars.”
Really? I thought there was an entire industry devoted to fabricating positive reviews. For that reason, I skip past the five star reviews and go straight to the lower-star reviews that weren’t bought and paid for to see how appropriate they are. If they hint to singular bad experiences that don’t really reflect on the product or someone who is clearly just an idiot (for example, someone who doesn’t understand that noise-cancelling headphones won’t block out the sound of someone crumpling paper next to them, or someone who complains about speed of delivery) then I take that as a good sign. But if they’re valid complaints about the quality of construction, for example, then I take heed.
There are also cultural factors. I can’t speak to how true it is, but I’ve heard that in Japan, you want to shoot for about 3.5-star restaurant reviews. The 5-star places are review-bombed by tourists with no taste. But for the locals, 3 or 4 stars means the place is excellent.
I guess there is the problem that if it is a tourist trap with 3.5 stars, it’s probably awful.
Many of you have raised excellent points which show how untractable the underlying complications can get. Thanks for drawing my attention to these issues which I hadn’t really considered.
To rephrase, my question is “is there a mathematical formula that could help make the scores more legible, assuming - again - that the reviews are unbiased, thus leaving aside malice, stupidity and misunderstanding ?”
For such a mathematical formula, you would first need some model for what you would expect ratings to be for a random product. For instance, you might assume that a random product would be equally likely to actually be 1, 2, 3, 4, or 5 stars.
One simple way you could deal with the uncertainty, then, would be to add some number of average “phantom ratings” to every product. I’m unsure of the proper number of “phantom ratings” to add, but let’s suppose, for simplicity, that it’s 1.
In this case, a product with only one rating, at 5 stars, would effectively have two, the 5 and a “phantom 3”, for an expected true rating of 4. On the product with a thousand ratings at an average of 4.5, however, the phantom 3 would have almost no effect on the true rating, and so with the phantom rating, it’d still be 4.499 or so. Thus, the product with the 4.5 is probably better.
I don’t know if it’s true in Japan, either, but I do that kind of thing here in the US. Usually, I find my sweet spot is about 4.2 ±0.1 stars for restaurant reviews, particularly ethnic ones. Once you dip into the 3.5/s, though, it can get a bit dicey.
In regards to 1 star vs 5 star reviews, I just look for the overall shape of the distribution. When I see a pretty typical declining progression from 5 to 1, that’s a pretty normal shape and I trust the score for the most part. If there’s two big spikes at 5 and 1, then I’m wary of the score, though it takes reading some of the reviews to see if it’s being manipulated in either direction. What may be overlooked is how many 2s there are. Review bombers are going to go straight for the 1, but if I see a blip in the 2 ratings in addition to the 1s, I tend to assume the ratings are probably honest ones.