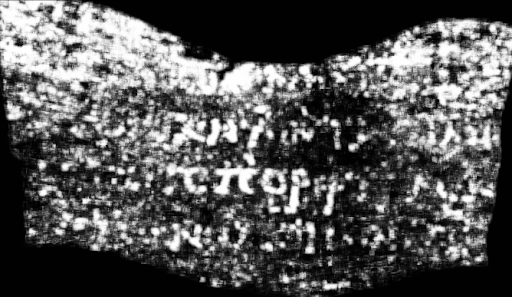This is very cool, and has real potential to unlock a lot of manuscripts that were previously inaccessible. For example,
More broadly, the machine-learning techniques pioneered by Seales and the Vesuvius Challenge contestants could now be used to study other types of hidden text, such as cartonnage, recycled papyri often used to wrap Egyptian mummies.
My mom took a cruise that included Ephesus. The guide pointed out that one ruined building had a large foot shape carved into the threshold. He explained it was for a brothel, as a way to separate men from boys.
That article really needs more detail about how “AI” did this, in order for me to consider it significant. Is this an actual scan of the actual ink, or is it ChatGPT giving its own impression of what the scrolls might say? If a scan of the actual ink, why was the decoding done by “AI”, instead of by deterministic computer programs, which would seem at first glance to be much better suited to such tasks?
Because the scrolls are so highly damaged. For one thing, they’re still in scroll form. Unrolling them would destroy them completely. And second, there is no ink left, as such. Just an extremely subtle difference in texture as recorded by the CT scan.
There’s much more detail here:
That was from a few months ago; the latest news is just that they completed decoding several of the scrolls.
The systems used in this project have absolutely nothing to do with Generative Text AIs like ChatGPT. The system uses AI to distinguish ink from substrate, which is amazingly difficult - the ink was carbon-based, had no iron inside (thus it does not show directly in the scans), and basically the only way to distinguish ink from substrate is by detecting the scratches left by the pen on the surface of the page.
Doing that by means of a deterministic computer program would be beyond an absolute nightmare. Having an AI that trains itself to detect the scratches is much better.
The results have been cross-checked by diverse teams. And if your worry is that the AI used somehow “hallucinates” the results… given that what it detects is not writing but simply the scratches on the surface of the papyrus, if it began to hallucinate stuff the recovered images would not be text, but an absolute nonsense of random lines.
I don’t think that’s quite true, either. The models are trained on ground truth data, and have some idea of what the letters look like. If you match a noisy image against a limited set of possible letters, it’s possible that the model will “hallucinate” a letter that wasn’t really there.
It’s even possible the model is learning what letters are more likely to form adjacent pairs, and pick out data from the noise based on that. For instance, say (in English) you have what you think is the letter N, but follows the letter T–in that case, what you saw is probably an H, since the TH pair is much more likely than TN.
One could, in principle, imagine this sort of predictive analysis working at higher and higher levels, to the point where you worry it’s constructing paragraphs of text from way too little data. But that would require a model with the sophistication of ChatGPT if it’s not to produce total nonsense. And that’s not what they have here.
This is very interesting but I feel like I’m missing something here. How can they scan the very most inside parts of the scroll (under many layers of scroll) without unrolling it? I can see being able to read the first few layers on the outside but how can you scan the lower layers?
At first I thought they were reading one “layer” at a time and then unrolling (destructively) the part already read and then moving to the next layer down. It seems this would destroy the scroll but could allow for the whole thing to potentially be read.
But is it possible to do this non-destructively and read even the inner-most parts without unrolling? That seems close to impossible. I guess I don’t understand exactly what they have done here.
I get the basic procedure for using machine learning to identify many of the letters I just don’t see how that can be done beyond a few layers deep.
They have an extremely high-resolution X-ray machine. No different than a CT scan at a hospital, just with a lot more pixels.
The trouble is that you end up with a solid lump of data, not individual pages. You need sophisticated decoding (or tremendous human effort) just to separate the pages, let alone decode what’s on them.
OK, I think I get it now… It’s an ill-posed inversion problem? There are many possible arrangements of scratches that could produce the CT signal they got, and they have to figure out which one is the true one?
Any ill-posed inversion problem relies on adding more information from somewhere. Some of the extra information can come from basic physics, things like “the density is nowhere negative”. And some can come from simple observations like “this is a rolled-up sheet of flat material, so the density profile should be close to a bunch of almost-concentric almost-circles”. But that’s usually not going to be enough information. You have to add more information, and you have to be careful in the process that you’re not just seeing what you expect to see.
If I’m understanding correctly, they used the information that the density variations came from letter-shaped scratches, but did not (knowingly) use the information that the letter-shaped scratches formed intelligible Greek text (and the AI was not trained on a large corpus of Greek text). And despite not being trained to produce Greek text, the output of the AI nonetheless consisted of intelligible text, which provides confirmation.
Per the link above, they had identified Greek in a fragment already. Amd, they revolved it and scanned it in 360 degrees, so they had a bunch of images to work with, and the need to make any interpretation consistent across them. Definitely a machine learning kind of problem
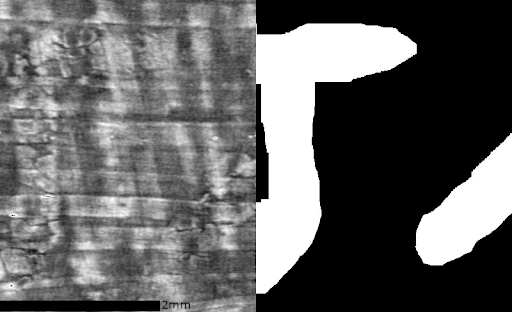
One of the key insights was the observation of “crackle” in the inked areas. The first decoding came from a human observation of this, and then manual labeling, like this:
Luke Farritor trained his model on the manually labeled data, then ran it on a larger section, producing this:
I don’t think Luke knew anything about ancient Greek, and his model certainly wasn’t trained on that. But it produced clearly intelligible letters.
I am irresistibly reminded of Inherit the Stars, a 1977 SF novel by James P. Hogan. The protagonist becomes involved in the investigation of a bizarre discovery on the moon because he had just developed a prototype CT-scanner-like device, and they needed him to use it to read ancient documents too fragile to open. Several scenes in the early parts of the book revolve around the painfully slow human analysis of the scans and developing models to enable computers to extract the text instead.
(ETA: I just checked, and the novel is set in 2027. Hogan may have been a crank, but I think we can say he scored a sci-fi bullseye with this one.)