Could someone help me out on a small project? I’m comparing output for a prompt in several models. The fairly simple prompt I chose is mostly meaningless and chosen just because it might produce something kind of unusual. I have already tested it in SD 1.5, SD 2.1, SDXL, Dall-E 2, Playground, and Craiyon and will test it in Kandinsky in a couple of hours when I have fresh credits. I want to try it in Midjourney, but don’t have an account. So would someone mind generating four Midjourney images with this prompt?
Scary ugly monster girl by Dan Witz, Mark Ryden, Margaret Keane, Pino Daeni, Picasso
Go for it. I evolve some pretty weird prompts in the quest for generating pretty weird images. This prompt should entertain you, too:
Calavera tardigrade | wide shot | by Dan Witz, Mark Ryden, Margaret Keane, Pino Daeni, Mab Graves, Carne Griffiths | Professional photography, bokeh, natural lighting, canon lens, shot on dslr 64 megapixels sharp focus
(You may need to use “frame” as a negative prompt on that–Mark Ryden art often features frames and SD knows it.)
Fairly recently in a batch of 16 of those (in SD 1.5) at Night Cafe, I got this:
Which I expanded in Playground until I had this. I could never have expected boob windows with damned souls trapped inside to crop up. (Anyone who says AI can’t be creative is a Dunning-Kruger twit):
Creating variations on that final image with the same prompt and varying levels of noise can generate very interesting things.
Variations on tardigrade-based prompts can produce all sorts of weird creatures. And if you create them at a lower resolution (like Night Cafe’s 576x384) and then enlarge the frame to 768x512 or 1024x1024 and infill at Playground, it will generate new creatures similar to the old one. I’ve done many of them, here is one collage I had handy.
Which using the expand/infill method resulted in things like this. I would infill for a while using one image until I liked one of the new results, then would start using that new one as the example for the infilling. (I cropped many images where there wasn’t a smooth filling between the two characters.)
So here’s what I have right now. You see that each AI gives a significantly different range of results for the same prompt. Some things of note:
Craiyon has improved significantly since it was just Min-Dall-E. And there is apparently a newer version available than the v2 I used.
Playground continues to put out overly-dark images.
Kandinsky produces detailed, coherent images that are significantly different from the other AIs, but there isn’t a lot of variation from one Kandinsky image to the next for any given text-only prompt.
Thanks. I’ll add some of the Midjourneys to the sample. The samples from the addition renderer are appreciated, but no room to add them to the sample without reformatting it.
Using this (above mentioned) prompt in img2img with various amounts of noise in SD 1.5 and Playground produces satisfyingly weird results.
Summary
Calavera tardigrade | wide shot | by Dan Witz, Mark Ryden, Margaret Keane, Pino Daeni, Mab Graves, Carne Griffiths | Professional photography, bokeh, natural lighting, canon lens, shot on dslr 64 megapixels sharp focus
The original is an image of a cat riding a frog created in SDXL. I think both of these results were from Playground. The second one was outpainted in SD 1.5 to widen the image
Two photographs of one of my cats. These are a mix of SD 1.5 and Playground. I don’t really remember which is which, both gave similar results.
Not with this exact prompt but with a very similar one SDXL generated an image that looked much like a young Princess Leia.
I expanded the frame on the 512x512 image to 512x768 and infilled it using SD 1.5 at Playground. At first I was trying to get something similar to Leia’s white dress in ANH but that wasn’t giving me anything I liked so I went for other clothing styles (it didn’t need any of the complexity of the original prompt–a prompt of just the word “girl” is enough to get a style-matching infill). That got an image to around lower waist level, a second cropped and infilled image dealt with the lower body. I then filled in the sides to get the images to a 2:3 aspect ratio.
(Prompts using Princess Leia generated utility belts and blasters and droids to the side, but they were very badly rendered utility belts and blasters and droids.)
On a “famous people” note, I discovered that some of the AIs have a pretty good idea of what Fred Rogers looks like. (Seems like there are plenty of posed publicity shots to learn from.) Playing around with my complex “calavera x” prompt, I started plugging in TV show titles. Here is one I got for Mister Rogers. (“Neighborhood” wasn’t in the prompt.)
I’ve been playing around with Kandinsky 2.1 (within the restrictions of being able to make only 10 free images per day) and today I scrolled through some old prompts to find something to try. I stumbled on a Cyberpunk Elf Gibson Girl prompt variation, so here it is in Kandinsky:
And here’s a sampling of other Kadinsky images (some prompt only, some img2img):
Kadinsky is a mixed bag. Some images are amazing, some are not. But it has much less variety in output than other AIs–the same prompt (with different seeds, of course) tends to generate images much more similar to each other than in other systems so there isn’t much point to generating multiple versions. (There seems to be more variability in img2img, though.)
Also, I’ve found that SD 1.5 does a damn good job of matching the styles of other renderers in inpainting/outpainting. Here is a completion of the Kadinsky Gibson Girl’s hair via SD 1.5.
And another example from a few days ago, I used SD 1.5 to turn a segment of a Kadinksy image from this













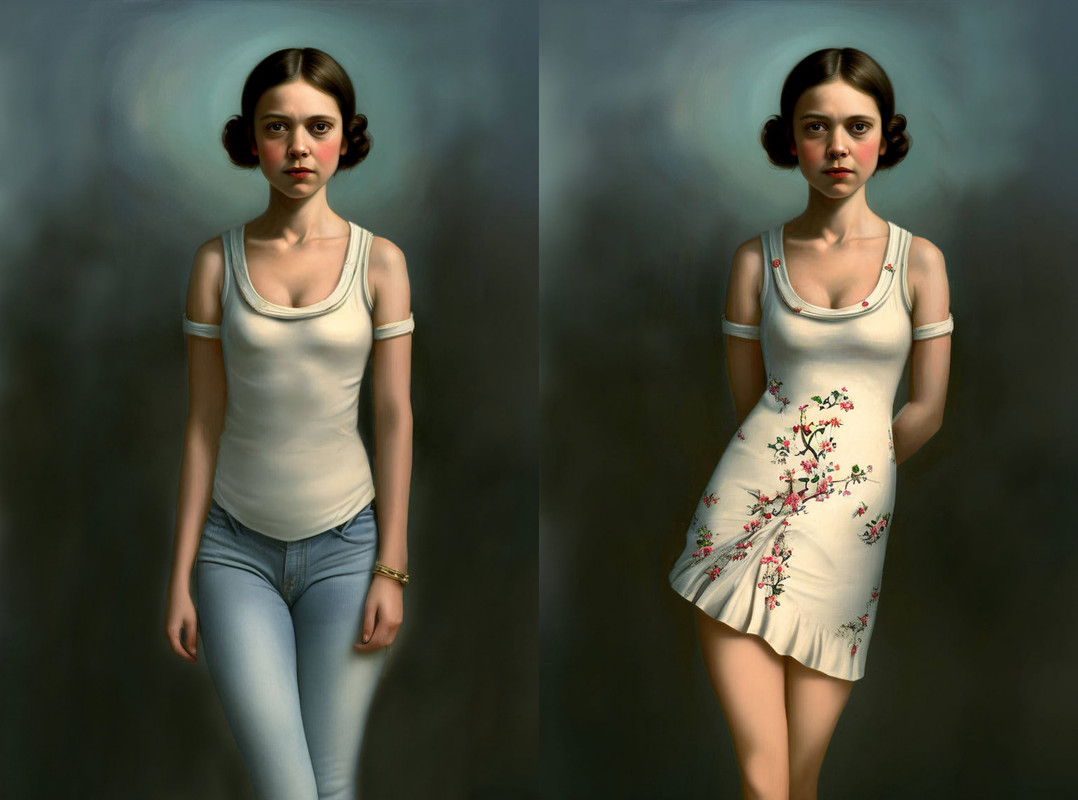








{kind=link}