There are four pairings in a DNA backbone, C-G, G-C, T-A, and A-T.
A sequence of DNA can have any of the four in any sequence.
C - G
T - A
C - G
A - T
G - C…
I’ve seen sequences in which one of the four is repeated.
C - G
T - A
C - G
C - G
C - G
A - T
G - C…
Is there any limit to how many times one particular pair can be repeated? If so, why and what it is? If not, why? And what is the largest number of duplicates that has actually been found?
IANAB but I have studied a bit of cell bio, mol bio, and bioinformatics.
In principle there’s no limit. In practice, bad things can happen if you have too many repetitions. The DNA replicating enzyme and the DNA strand being copied, are constantly being bashed around by random thermal motion of the water molecules around them. If the bashing around causes the two strands to get a base or two out of sync, that’s normally not a problem as they can easily recognise the right position to get back into. But if you’re halfway through copying a sequence of a few dozen 'A’s and the complementary ‘T’ strand gets knocked one or two bases out, it won’t see the mistake.
The upshot of all that is that when you have long repetitive sequences (and I think it can happen with 2-base sequences too, e.g. CGCGCGCGCG…) the copying fidelity gets shaky. Each replication the length will vary (and I think there’s a trend upwards for some reason - maybe just good old momentum?). This’ll cause problems of varying degrees, but particularly if it’s in a protein coding region. Eventually the protein would just be buggered up, and they’re kind of important. The word “Huntington’s” is swimming into my head here.
Scooting off to wiki, Huntington’s is actually due to a repeated THREE nucleotide sequence, CAG. The gene affected is usually called HTT but sometimes also called ‘IT15’ which stands for “Interesting Transcript 15”. I wonder what the DNA polymerase has to say about that.
I don’t know that, but I know people have looked at the list of courses I took and said slowly, “hmm, interesting transcript.”
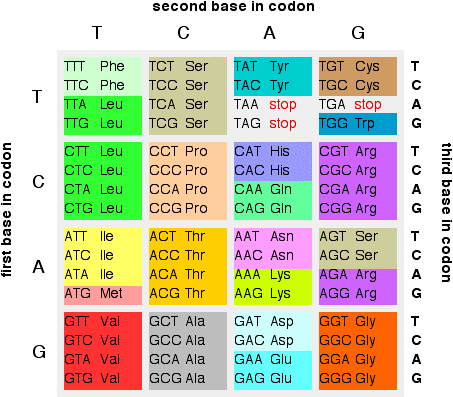
During protein coding sequences each group of three base pairs codes for a specific amino acid in the target protein (see the code here).
So if the repetition was in this area and did not code for a meaningful sequence of amino acids, you would have deformed proteins. If it was in a sequence of junk DNA (non-coding DNA) it likely wouldn’t have any significant consequences.
ETA: This is a vast over-simplification of course. There area areas of non-coding DNA that control the expression of genes (among other functions). Unusual or excessive repetition in those areas could very well cause problems with down-stream gene expression.
As has been said, in theory, there’s no real reason why you couldn’t have a million As in a row. In practice, that would cause several problems. Polymerases (enzymes that read and copy genetic material) tend to lose their place in long stretches like that, resulting in the length changing (either adding or losing some). Additionally, the AT pair has two hydrogen bonds, while the GC pair has three, making it a stronger bond. Because of this difference, long stretches of GC pairs are unusually stable, while long AT stretches are unusually unstable. This can have consequences for the cell. You generally see a characteristic GC:AT ratio that is more or less consistent throughout a genome.
As has also been said, a long stretch of a single nucleotide can only code for a single amino acid, over and over, but since most of the genome doesn’t actually code for proteins, that’s not a dealbreaker.
Also, trinucleotide repeat expansions are characteristic not only of Huntington’s disease, but also of many other degenerative neurologic disorders. It happens in Fragile X, too.
{kind=link}