ChatGPT is still iffy on my particular use case, where I was telling it to draw scenes of the story we were developing, and the contents of the screen were somewhere in the context.
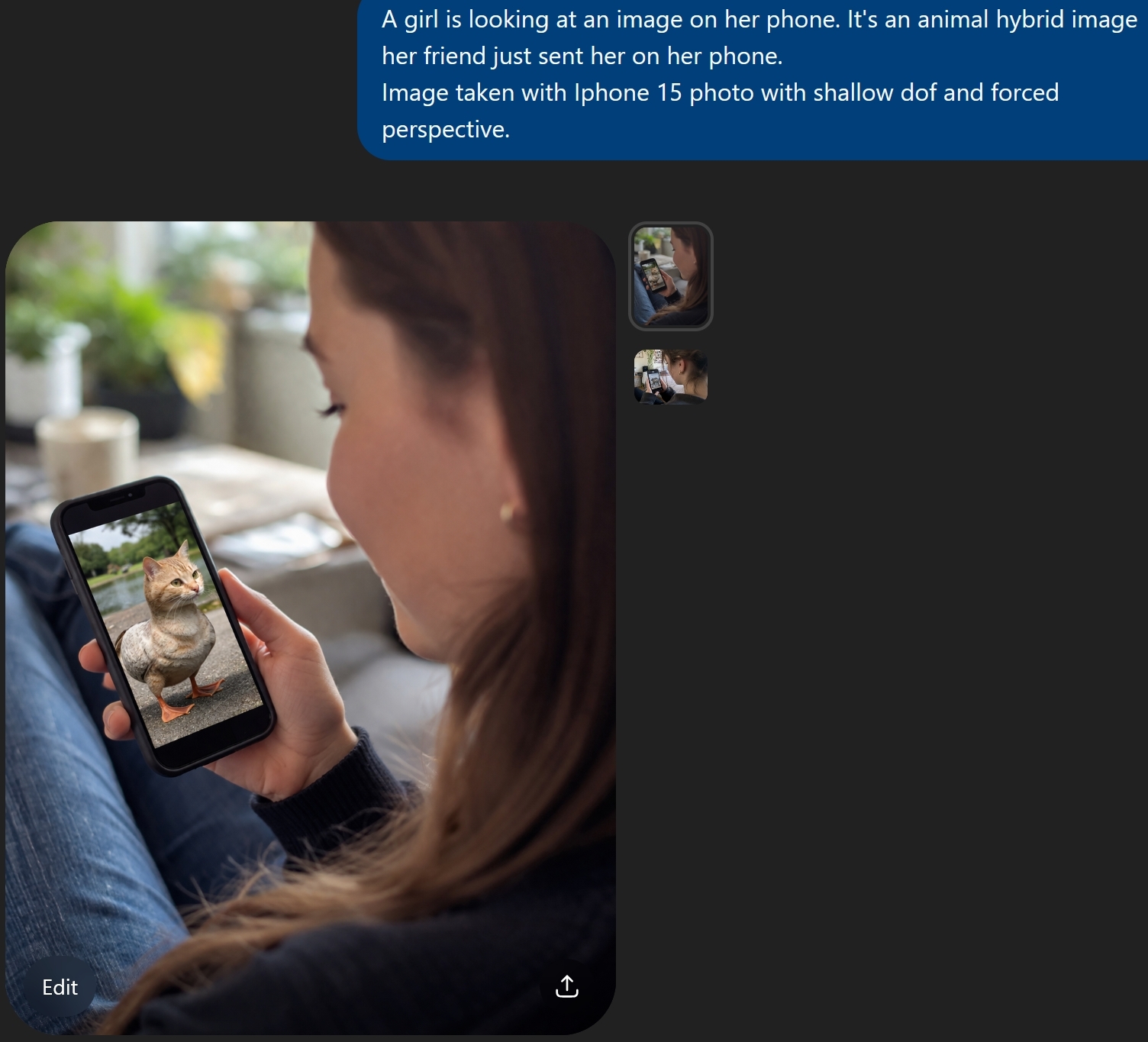
At least now it shows her holding the phone with its screen facing the camera, and not a screen on the back of the phone.
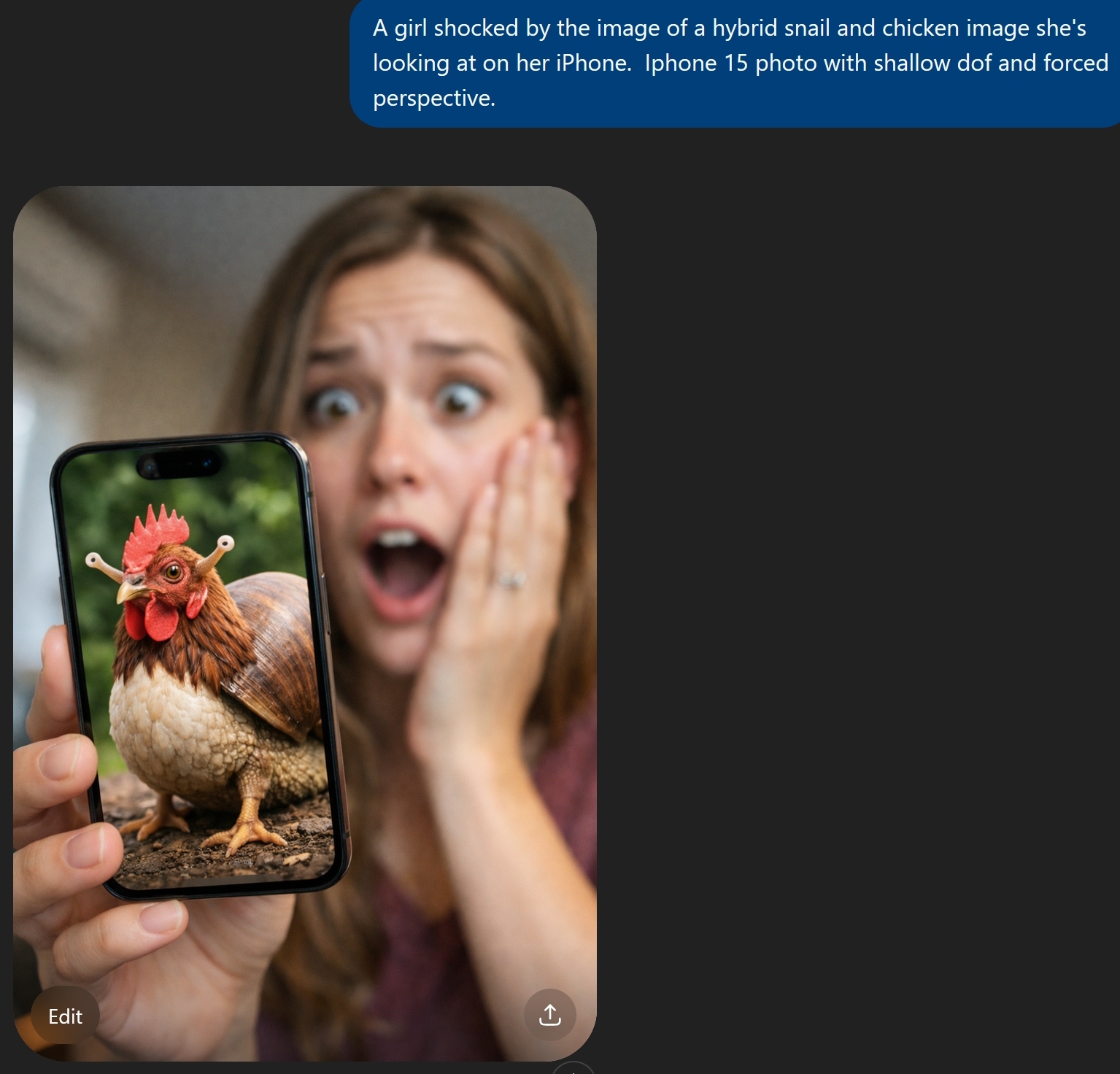
Over the shoulder photo of A girl shocked by the image of a hybrid snail and chicken image she’s looking at on her iPhone. Iphone 15 photo with shallow dof and forced perspective.
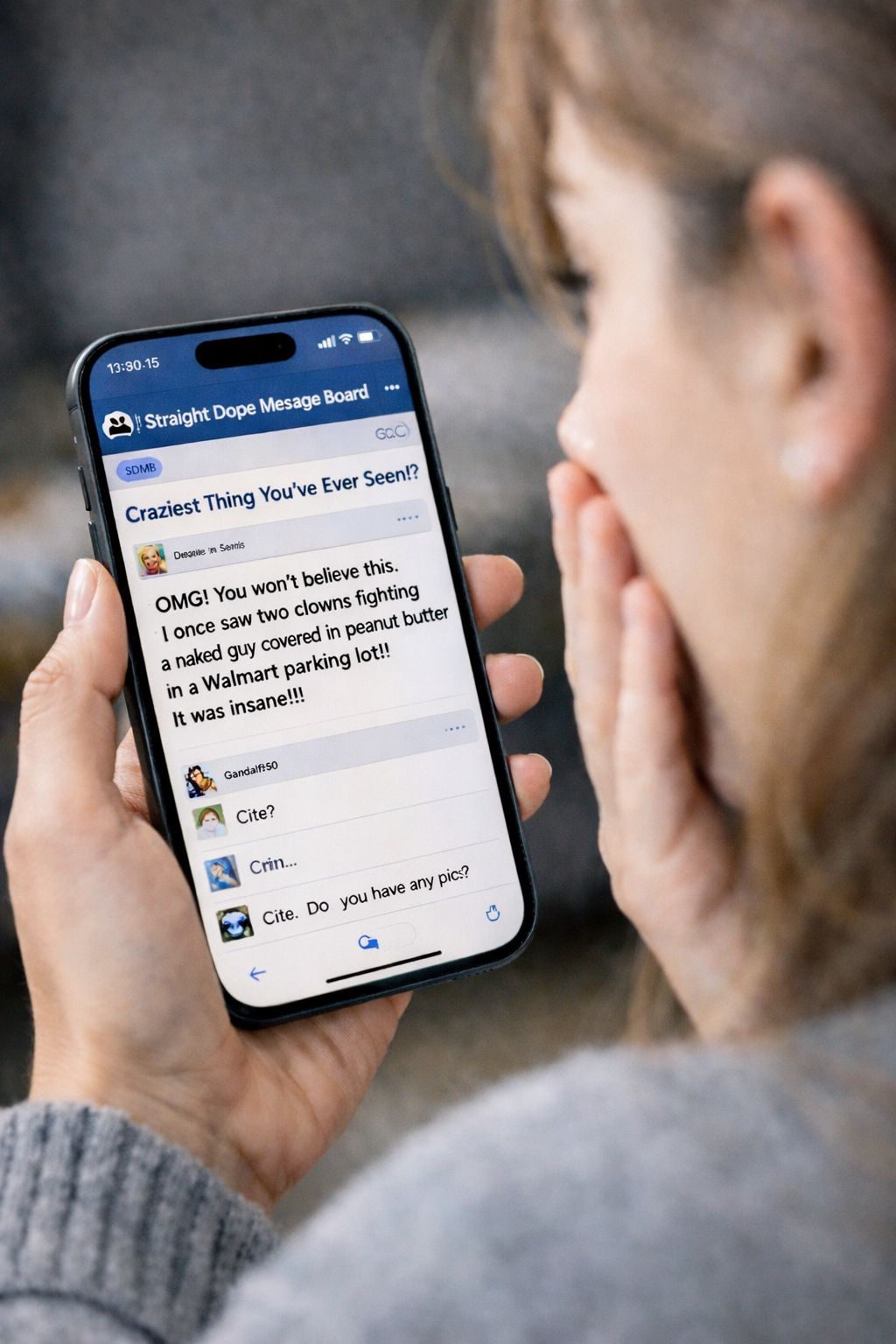
Over the shoulder photo of A girl shocked by a message thread on the SDMB she’s looking at on her iPhone. Iphone 15 photo with shallow dof and forced perspective.
I mean, if you tell it what the phone-viewer’s emotional reaction is, we want to see the person’s face. Seeing a person’s facial expression is much easier from in front of the person than from over their shoulder, but a view from in front of the person naturally excludes seeing the phone screen. So the artist must make a choice between showing their emotional reaction is better, and showing what’s actually on the screen. I’m not so sure that the AI chose wrong.
If you don’t specify the emotional reaction, then there’s not as much priority on seeing the person’s facial expression, and so the weight goes back to looking over the shoulder. And if you explicitly say to look over the shoulder, that also pushes the weight towards that, even though you now can’t see the expression as well.
Here’s my suggestion for how to handle that. She’s looking in the direction of the camera, but down at her phone. Her phone is facing her. We can’t see the phone’s screen, only the back of it. But we can see is the reflection of the phone in the glass behind her, and that, while not totally clear, shows us enough that we can make out what the shocking image is.
I had it generate a port city for me. Once I tweak by prompt it gave me a very serviceable town.
Prompt: create a picture of a Port City with large stone docks. The docks are U shaped and open to the North. They harbor cuts into the city. The City has stone walls and is roughly a 1 mile diameter. Wooden Sailboats line the docks. No visible church steeples. Only Gate is in the center of the south wall.
Yeah, it’s not there yet. It’s amazing what AI can do now, but it still has what seems to me to be an obvious AI look, especially in facially expressions and the dead eyes of its renderings.
But in 10-20 years? It’s scary. Real photos can be dismissed as AI, AI images can be indistinguishable from real photographs. We will be living in an even more post-truth world. Or a post-reality reality. It’s an interesting philosophical and existential question when we can’t trust anything but what we first-hand witness, and not even 100% that.
It’s not a new question, though: That was just as much the case before the invention of photography. And even with AI images, we’re still a lot better off now, truth-wise, than we were in the pre-photography era.
It used to be that, if a person said “I saw the guy who shot the murder victim in the head, and it was Fred Rogers!”, we (or the police or a jury) had two questions to consider: First, was the witness honest, and second, was the witness mistaken. Only if you believe that the witness is both honest and accurate would his testimony be relevant.
Now, though, if someone comes forward with a video of Fred Rogers shooting someone, we still have to question the witness’s honesty, because they could have faked that video. But if we accept the witness’s honesty, then we don’t have to question their accuracy, because even if you can fake a video, an honest witness wouldn’t have done so. The video still has considerable value.
Yeah, I have considered how it used to be, but I feel this is different and much more difficult. I’m questioning everything I see or hear in a way I hadn’t before. My literal perception of reality and what is and isn’t real has markedly shifted. This can be both good and bad, but I think it has much more potential for abuse than the other way around.
So, I just noticed that you’re not the first person to create an image of a tribearatops. There’s also one on page 45 of the D&D 3.5 edition Spell Compendium, way before the AI era (there, it’s the result of a spell cast on a druid’s animal companion).