They have also tinkered with how images are presented again. You may have noticed that they switched between .png and .jpg several times in the past. Up until a couple of days ago, a right click (or long press) and “save” downloaded a jpeg. Now it downloads a png again. (Not to be confused with saving it from the drop-down menu, which has been png for a long time.)
Meanwhile Night Cafe has introduced SDXL 1.0 as a paid-subscribers-only option.
An annoying thing (to me) about SDXL, at least locally run, is that it expects around a 1024x1024 resolution and gives worse results at lower scales. This means it takes far longer to run images than SD1.5 at 512x512, plus the additional SDXL step of running it through a separate refiner. Granted, this is all user dependent – I’m just rendering stuff to say “Neat” and likely never look at it again so there’s not much added value in the images being at 4x the resolution but an obvious drawback in it taking 4x as long to see if the idea/prompt is even any good.
Does SDXL take significantly more credit on sites using points/credits or other limits?
Playing around with SDXL for a few days (and not using any custom models or Loras yet though some must exist by now) my impression is that it’s better than any previous SD but still not up to the quality standards I see from Midjourney, especially for artistic vs photorealistic images. For photorealism, they’re probably about equal but I haven’t been super impressed with how SDXL handles multiple artists in the prompts.
At Night Cafe, SD 1.5 costs 0.25 credits per image when ran in sets (as in 16 images for 4 credits) or single images are free (all at base resolution). The SDXL beta forced higher resolution and charged 3 credits per image (so 12 times as expensive). Now that full SDXL 1.0 is out, they charge 1 credit, but it is only available to paying customers, not for use with free daily credits.
On Clipdrop they put a big watermark on the image unless you are a paying customer.
At Playground, it is as free as the older versions.
It seems that SD 1.5 is trained with all sorts of porn while SDXL is not, at least on Playground AI.
On a whim, I used as a prompt, “2 girls, 1 cup” and held my breath. The SDXL results were excellent - a bunch of Victorian ladies looking at the same ornate tea cup and things like that. On SD 1.5 … I fully expect a visit from the FBI. Listen, I’ve never actually seen the 2 Girls, 1 Cup video. I’ve actively wondered if it’s even real or if it’s like Church of the Subgenius thing, where you’re sworn to claim it’s real, but the real link is a bunch of fluffy kitties or something. That said … SD 1.5 spit out some downright disturbing images. A lot got “safetied out” but some didn’t. I quit after three successful images because I was getting grossed out.
Speaking of Playground, you may have noticed that they added this notice for when you edit images:
This is a direct result from someone with no clue how diffusion models work trying to make a type of edit at Playground that (I assume the default of SD 1.5) was never designed for and then going viral complaining about the results in a poorly-researched newsish piece.
More new filters have showed up at Playground AI. There was no pre-hinkiness to portend the change … I’ll have to figure that out. I’ll check my notes thoroughly. Anyhow, I have no idea what they do yet, but I love and hate new filters. A) I love new filters; they’re fun and it’s exciting to bake them in to my little algorithms, but 2) now I have to update my spreadsheet to include nine new filters and figure out a new optimum algorithm for premium pieces, and Finally) I need to get a life.
All trained for SDXL, too. They have lots for 1.5 but only 2 for SDXL 2.1. I don’t know why they don’t have Realism Engine, which is one of my absolute favorites and is for 2.1. I have to use Dreamlike for that one.
I’m sure most of you who would be reading this remember Google Deep Dream, one of the first AI image generators to get a lot of attention several years back. I’ve been playing around with using “google deep dream” in prompts on SDXL, with very cool results.
Here is “ugly cute scary funny weirds polaroid kodachrome ektar google deep dream”:
As much as I like these (and I made generated dozens more than this set) I wanted to try for some without a few of the images containing cameras and a lot of them containing creatures with lens eyes. I tried the same prompt except without “polaroid” and ended up getting much different images:
Then I tried the full prompt using the earlier of the SDXL betas still at Night Cafe with radically different results:
And here is the full prompt in several other systems. Some interesting results, but none as good as full SDXL.
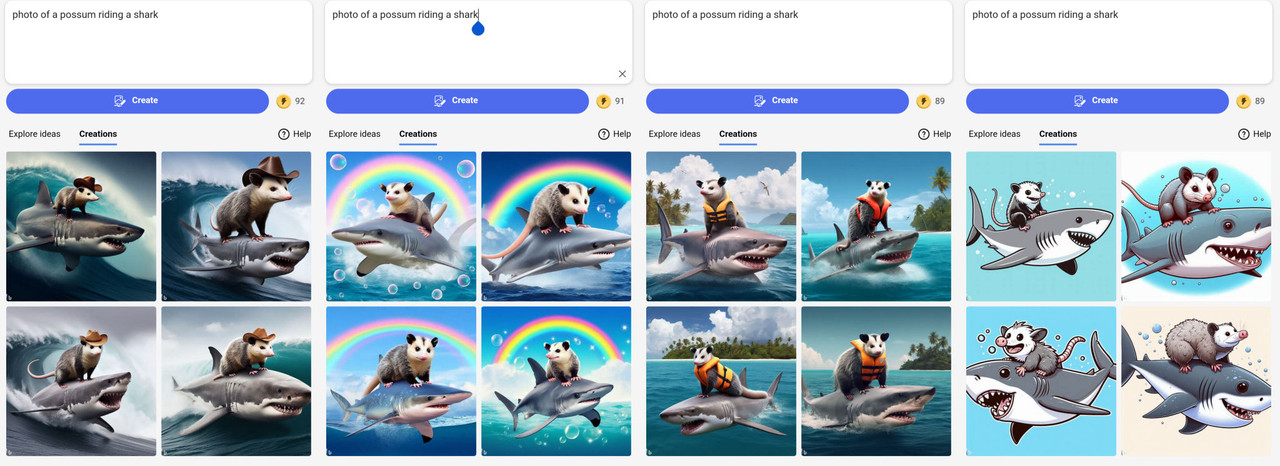
Dall-E 3 has been added to Bing, and it is weird. It produces some pretty amazing images, but it seems to like adding odd, unrequested items to prompts, clumped together in “themes”. I’ve just started playing with it, but for example in this simple prompt for a photo of a possum riding a shark, in one set all of the possii have cowboy hats, in another they are all wearing life vests, in a third there are rainbows and bubbles and in a forth all are drawings.
Someone else has posted images where signs (with clearly written phrases) were added to images unprompted.
(I had been calling what Bing already had “Dall-E 3” because the results were very different from Dall-E 2, but this js het again a big change.)
(Here’s the article that led to my new experiments)
I did a quick test in Bing: “Draw a cartoon of Warren Zevon playing guitar on stage”
There were several different ones, all about as good. Really impressive. If I saw that illustration alongside an article about Zevon, I would think it was human illustrated.
Yeah, I’ve had similar experiences with very well done drawings, like this possum riding a tyrannosaurus.
This is reaching the “ready for prime time” stage. (One failure, though: asking for the possum to be riding a brontosaurus or apatosaurus also generated images of a possum on a tyrannosaurus or Spielberg-style velocitaptor.)
About understanding more complex prompts, one of my first tests was "a possum holding a sign that says “cat” and a cat holding a sign that says “possum”.
I don’t need to create examples in other models to know that they would mangle the results.