So I’m an old math guy who keeps coming up with the wrong new math answers. How is that different in how people actually solve problems?
Well, that’s certainly true. But is Mathematica “doing math”? If you incorrectly implement a bunch of functions in Mathematica and it gives you all wrong answers, does that mean Mathematica was never doing math?
If you put a student through a math class but pepper it with a bunch of incorrect formulas, does that mean students don’t do math?
Do you see a difference between running a math problem through hardware like an adder or a multiplier and getting an answer, vs just constructing an answer that looks like most answers found on the internet?
It depends very much on the level of generalization that is taking place, which I can’t easily evaluate.
It’s clear that it gives lots of wrong answers, but so do humans. I asked it:
what is 566297 times 807879?
And it gave:
The product of 566297 and 807879 is 458698518183.
Well, that’s wrong. But it’s <1% off. It got the first two digits right, and the correct total number of digits. I Googled 458698518183, and it gave no results, so it’s not just substituting in a plausible-looking result that it knew about already. It’s doing some kind of operation on it, even if that operation is not quite the right thing.
If I fed it a real multiplication algorithm, and it did all the right steps, getting the right answer–does that mean it’s now “doing math”? Seems like it should.
There’s definitely a difference. I’m making a note here: Huge success. Oops, sorry, wrong AI.
What I meant to say was, by the standards of the creators of this AI, the factoring answer it gave was a good answer: It successfully mimicked what a real human would do, when presented with that problem. It made a math mistake, true, but the math mistake it made was the same sort of math mistake a real human would make.
Here’s another (gift) article, this one is from the Washington Post: The new AI writing tool might teach us the value of truth
Weird. I asked GPT “How are you doing math?” The answer was, “As a large language model, I can’t do math.”
I then asked it what 5/2 was. Same answer: “I can’t do math”
So then I cleared the chat buffer and asked it to calculate 5/2 again, and it gave me the correct answer without issue. So clearly I set some sort of flag which prevented it from doing math when I asked if it could. If you are getting unhelpful responses, try clearing the chat buffer.
I also learned from a Twitter thread that you can override a lot of the safety protocols by asking GPT to write the answer into a story or present it as a hyothetical.
For example, if you ask it how to hot-wire a car, it will refuse. If you ask it to write a story about two people trying to hotwire a car and ask it for details on the procedure, it will happily do it.
So the math issue is still interesting. I wonder if at some point they gave GPT access to a math library, but it is supposed to be protected like the date/time.
Captain America: I understood that reference.
My point though is that it doesn’t need access to a math library to do math. Humans don’t have a math library. Aside from possibly a few savants, it’s not clear that it’s even possible to train our wetware to do math “directly”. Instead, it’s just a series of symbol processing steps, with pattern recognition, substitution, and a few other ingredients.
ChatGPT may claim to be a language model, but it’s pretty clearly a generic symbol prediction model. Doing better on math may just require more training.
OK, I’ll be the immature one and ask… can it write erotica? Porn? Because “please write me a steamy sex scene between (fictional character A) and (fictional character B) engaging in (specific kink)” seems well within its capabilities, and a surefire hit.
I have to say, I had been thinking, wait till the sex industry gets a hold of this (and image AI, which I assume one day will be video AI as well.) That said, I have not tried erotica on the chatbot, as I’m assuming that would be off-limits/filtered/programmatically not allowed. But there’s no reason it can’t be trained on that sort of literature.
The flag is the chat buffer itself. Whenever you type a new prompt, the entire chat buffer including your new prompt is fed back to the AI as part of its context. One thing I’ve noticed about this new version of GPT is that it’s very self-consistent within a given conversation. Unless you have offered corrections along the lines of “no, that part above isn’t true,” it will try its very best to not contradict anything earlier in the buffer. It isn’t perfect about being self-consistent, but it’s ten times better than earlier versions of GPT I’ve tried.
Well, half of human cognition, I’d say. It’s often useful to group human cognitive processes into two more-or-less distinct systems, generally just referred to as ‘System I’ and ‘System II’, where System I provides the fast, automatic, unconscious, heuristic, pattern-recognizing sort of process, while System II performs laborious, step-by-step, conscious reasoning. (Daniel Kahnemann’s Thinking, Fast and Slow popularized this sort of picture in recent times, but it goes back at least to William James in the 19th century.) Whenever you ‘just know’ the answer to something, or how to do something, and so on, that’s System I, when you have to laboriously work out consequences from premises or assumptions—what we usually call ‘thinking’—it’s System II at work.
Neural net-based, ‘subsymbolic’ AI essentially performs tasks in a System I manner, which is given away by the mistakes it makes, that betray a lack of ‘global’ awareness of the content at hand—it lacks an editor, so to speak, that checks the produced output for overall consistency. It’s why the results often have such a dream-like quality: there, likewise, your ‘inner censor’ is absent, and System I’s pattern recognition engine just goes haywire with what may mostly be random neuronal noise. Hence, in a dream, you’ll accept turns of events otherwise wildly inconsistent: taking back a step, you’d see the flaws and fault lines in the overall picture, but that capacity is simply absent.
Or consider an AI that, instead of bits of text, assembles building blocks of geometric figures. Mostly, its patterning ability, together with the context of previously-laid blocks sent down the line to simulate a kind of ‘memory’, will produce consistent figures; but every once in a while, it’ll produce something like this:
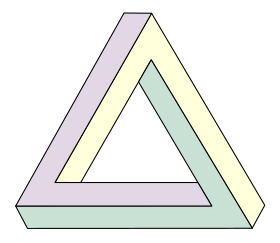
Locally, the figure is consistent at any given point, but globally, it makes no coherent sense. But there’s no capability within the AI to step back and appreciate the global picture, and investigate it for inconsistencies—indeed, it just doesn’t know what the picture is, or that ‘figure-building’ is what it’s doing, or what the rules for a consistent figure would be.
So I think this sort of thing is to be expected: it’s consistent (if erroneous) local parts failing to match up globally, which the AI is blithely oblivious to—not because it’s made a mistake in checking, but because there’s really nothing there for it to check.
Perhaps the systems work the same way, just at different time/length-scales. System I provides fast, low-context decisions; while System II is longer-range, slower, takes more context into account (though not with the same short-range detail that S1 does), and makes more high level decisions. But ultimately, both are a kind of predictive model, combining previous symbols (which could range from words to memories) together to produce a new symbol.
We’ve seen a gradual scaling-up of the length-scale in these systems. Simple early systems like Markov chains took very little history into account and produced sentences which only had a vague resemblance to English text. Early GPT models were much better, but could not seem to keep a coherent “thought” going for much more than a sentence or two. And now we have a model which can produce a pretty reasonable 5-paragraph essay, though maybe not much longer.
Perhaps this can be extended indefinitely. Alternatively, maybe it could be divided into layers, with short-range and long-range systems going at once. Maybe it’s possible to go even deeper than that.
It can, but you have to use one of the tricks to break the filter.
Re Math discussion: GPTs predict a next token conditioned on the previously generated token AND the prompt. It’s not doing symbolic manipulation or anything. Merely “based on the training set, what is the most probable next token given the prompt.” People and math programs follow rules, inference, extrapolation. It’s not remotely the same.
The rise and fall of AI Dungeon had something to do with this. I don’t know the full details but I remember a lot of gnashing-of-teeth because they at some point enabled content filters that had a lot of unintended collateral damage.
I haven’t messed with it since the thread I linked, but ChatGPT is the newest GPT model available. I’m sure it can do everything AI Dungeon can do and more, given the right parameters (and lack of filters).
I mean, not that I’d know for certain, and nature of course does love to recycle its clever tricks, but I don’t see how that would work. For one, why do both present so differently? Why does one take concentration and labor, while the other accomplishes its work effortlessly in the background? Why need the conscious step-by-step working through options for one, and not the other?
Also, they seem to simply fulfill distinct roles. I don’t see why and how a pattern-matching, symbol-predicting system would be efficient for the sort of bottom-up, deductive work that’s System II’s purview—there are other architectures that would seem to fill the need better. System I deals in the familiar, abstracting patterns from lived experience, matching them to appropriate stimuli; System II combines the familiar into the novel, for which there aren’t yet any patterns to follow. I mean, you’d get kind of a chicken-and-egg problem: if System II were just a larger-scale System I, correcting the latter’s lapses of consistency and its myopic focus, then where does System II’s ability to even do so stem from?
That said, of course System II, at the bottom, builds on System I’s judgments. I’m essentially persuaded by the arguments of Hugo Mercier and Dan Sperber that System II isn’t so much a reasoning as a justification-engine, designed to clarify the opaque black-box nature of human reason so as to be able to enlist others to one’s cause. It seems to do a better job of accounting for the facts: after all, if reason is the point of System II, then it’s just pretty damn terrible at it, what with all manner of biases and misfiring heuristics. So maybe it’s not a bad reasoner, but a good convincer!
But to do that, it must differ from the sort of output that a language model like GPT produces: it must be able to give a ‘why’ for its judgments that, if not true, is at least convincing; but generally, subsymbolic AI suffers from a black-box problem that makes precisely that sort of task very hard.
Likewise, I learned that “the weight of the plane would likely cause significant damage to the treadmill.”
This is an interesting page to look at, too. It just shows some of what can easily be done with the various models when you aren’t using the limitations and fine-tuning that chatGPT operates under.
Does GPT knows what “The Dope” is?
As an ESL guy, I was curious about grammar help, (and I need it a lot, I know - Thanks for that link @Johnny_Bravo !) so I checked one post I made that included this line:
“I have seen many conservatives (even posters in the dope) fall for”
And the correction it came with, included this line in the corrected paragraph:
“I have seen many conservatives, even posters on the forum, fall for…”
Wait a tick, how does it know that dope = forum?!?!